
Dans le cadre de nos activités archivistiques, il est essentiel de toujours chercher à moderniser nos pratiques pour optimiser le traitement des fonds documentaires et leur diffusion. Aujourd'hui, je partage une expérience qui mêle intelligence artificielle, gestion des fonds d'archives numériques et normes de description ISAD(G). Cette démarche se veut à la fois pratique et … Lire la suite N° 113 – Intégration de l’IA et d’AtoM pour la gestion et description des fonds archivistiques
Étiquette : Atom
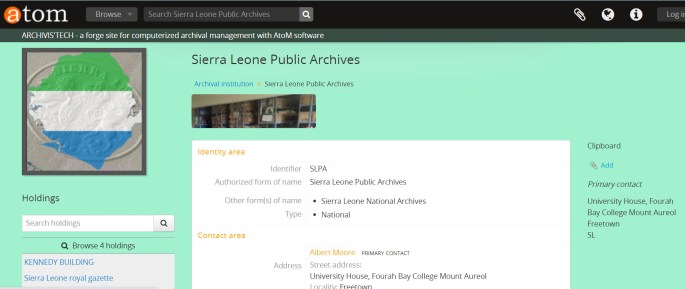
N° 99 – Ascension archivistique du Mont Aureol
La dernière semaine de juillet 2022 fut un moment où il me fut donné de joindre l’utile à l’agréable, tant du point de vue professionnel que touristique. J’eus en effet la belle opportunité de découvrir Le Fourah Bay College, université la plus prestigieuse de Sierra Leone (Afrique de l’Ouest), située sur le mont Aureol et … Lire la suite N° 99 – Ascension archivistique du Mont Aureol
N° 14 – RSS : agrégateurs en ligne
Suite et fin de ce mini dossier sur RSS par une présentation d'autres outils permettant de d'utiliser cette technologie PUSH. Pourquoi le choix des agrégateurs en ligne, parce que tout simplement ils ne nécessitent pas de téléchargement pour être utilisés, ce qui permet à tout un chacun de retrouver ses informations depuis n'importe quel ordinateur … Lire la suite N° 14 – RSS : agrégateurs en ligne
N° 13 – RSS : usages documentaires
L'usage des flux RSS dans le monde de l'information-documentation est plus facile à comprendre lorsqu'il est confronté à la mission essentielle qui est la nôtre, c'est-à-dire, la diffusion de l'information sous toutes ses formes. Depuis longtemps nous nous sommes appropriés les technologies informatiques pour donner une "nouvelle" identité à nos métiers, refondant nos manières d'être, … Lire la suite N° 13 – RSS : usages documentaires
N° 12 – RSS : une introduction
Parmi les possibilités offertes par XML, figure celle de pouvoir diffuser l'information par le biais des fils RSS. Pour une compréhension très simple, posons-nous des questions et essayons d'y répondre. C'est quoi, un fil RSS ? Combien de fois, chaque jour, ouvrez-vous par exemple Seneweb (pub gratuite) pour avoir des nouvelles et combien de temps … Lire la suite N° 12 – RSS : une introduction
N° 10 – XML et bibliothèques
A l'occasion des dix ans d'XML (10 février 2008), je profite de l'événement pour ancrer ma yole au port de cette syntaxe de balisage créée a l'initiative du consortium du Web qu'est le W3C. Je ne m'appesentirai pas outre mesure sur l'historique de sa création, tant l'information sur la question est abondamment disponible sur l'incontournable Web. Soucions-nous plutôt … Lire la suite N° 10 – XML et bibliothèques
